SQL (MariaDB, MySQL) [KOR]
DBMS (Database Management System) : 데이터베이스 관리 시스템, 소프트웨어
그 외 DBMS : MySQL, PostgreSQL, Oracle, SQL Server, DB2, Access, SQLite
데이터베이스의 유형
- 망형 (Network) : 계층형 문제점 개선, 1:1 1:N N:M 관계, 복잡
- 관계형 (Relational) : 테이블 형태, 유지보수 편리, 그러나 시스템 자원 많이 차지
- 객체지향형 (Object-Oriented)
- 객체관계형 (Object-Relational)
SQL은 관계형 데이터베이스에서 사용되는 언어이다.
정규화 (DB normalization)
- 중복되는 항목이 없어야 한다 (도메인이 원자값만으로 되어 있어야 함)
(2) 제2정규형 (2NF)
- 부분 함수적 종속 관계를 제거해야 함
(3) 제3정규형 (3NF)
- 이행 함수적 종속 (x -> y ->z) 제거
(4) BC(Boyce-codd) 정규형 (BCNF)
- 결정자이면서 후보키가 아닌 것 제거
(5) 제4정규형
- 다치 종속 제거
(6) 제5정규형
- 조인 종속성 이용
-- 형식) create table 테이블명 (칼럼명 자료형, ...constraint)
CREATE TABLE test(NO INT, NAME VARCHAR(10))CHARSET=UTF8;
-- 데이터 입력
INSERT INTO test VALUES(1,'홍길동');
-- 데이터 출력
SELECT * FROM test;
-- 테이블의 구조 확인
DESCRIBE test;
-- 현재 DB에 있는 table 정보 조회
SHOW TABLE STATUS;
-- 테이블 삭제
DROP TABLE test;
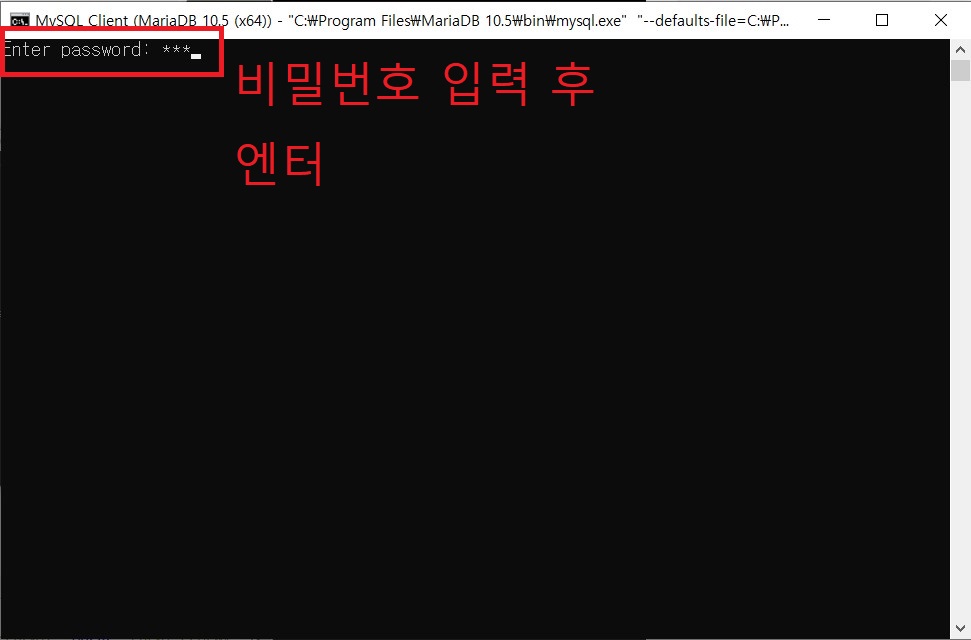
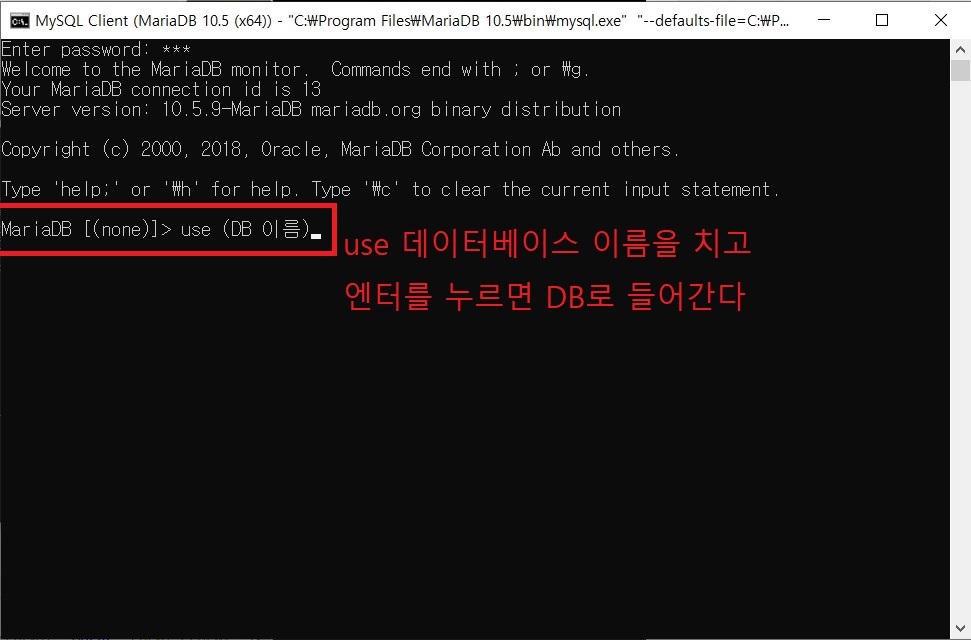
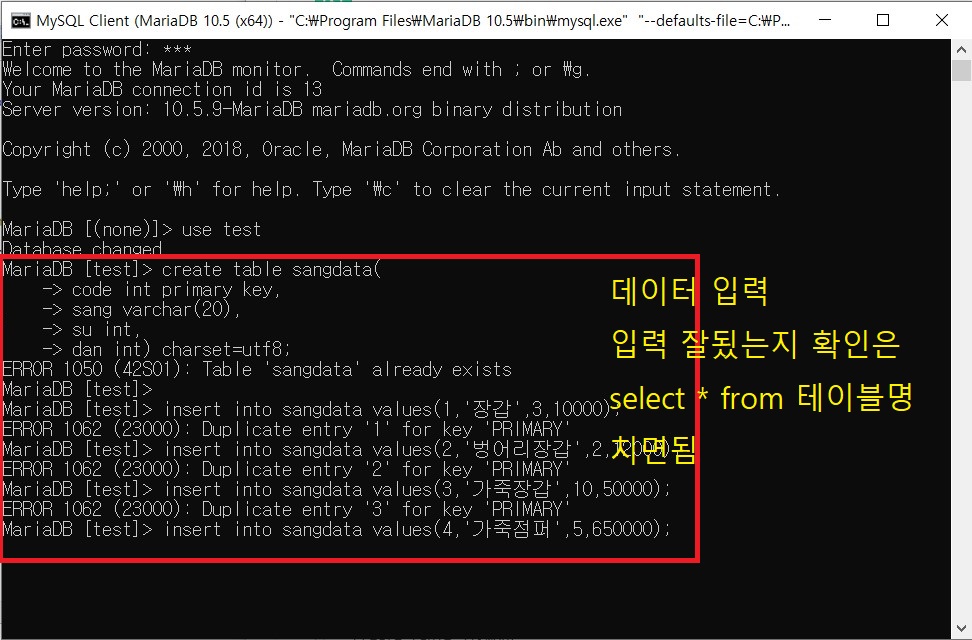
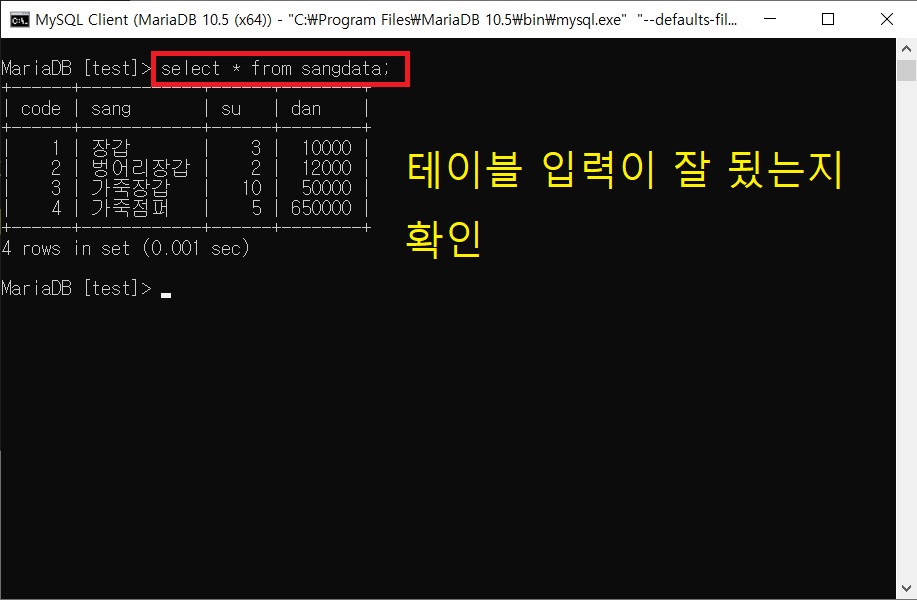
INSERT INTO test(no,name,tel,inwon,addr) VALUES(1,'인사과','111-1111','5','삼성동');
INSERT INTO test VALUES(2,'영업과','222-1111',12,'역삼동'); -- 칼럼과 순서와 갯수가 맞으면 안넣어도 된다.
INSERT INTO test(no,NAME) VALUES(3,'자재과');
INSERT INTO test(NO,NAME,inwon,tel) VALUES(4,'자재2과',3,'333-1111');
INSERT INTO test(NAME, NO) VALUES('자재3과',5);
SELECT * FROM test;
-- Error 발생
INSERT INTO test(NO,NAME) VALUES(3,'자재4과'); -- err : no는 중복 자료 불가. primary key 때문
INSERT INTO test(NO,addr) VALUES(6,'서초'); -- err : name은 NOT NULL 이기 때문
INSERT INTO test VALUES(6,'서초'); -- err : 칼럼의 순서, 갯수가 일치하지 않음
INSERT INTO test(NO,NAME) VALUES(6,'우리회사에서 가장 우수한 직원들만 있는 과') -- err : name은 10자리까지만 허용
SELECT * FROM test WHERE NO = 1; -- 1번 자료만 출력해줘 자료 수정 형식 : update 테이블명 set 칼럼명 = 수정값, 칼럼명 = 수정값,.... where 조건
UPDATE test SET intwon = 7 WHERE NO = 1;
UPDATE test SET intwon = 8, tel = '333-3333', addr = '역삼 1동' WHERE NO = 3;
UPDATE test SET intwon = NULL WHERE NO = 1; -- null값을 제공
UPDATE test SET addr = '' WHERE NO = 2; -- 공백이 존재
UPDATE test SET addr = NULL WHERE NO = 2;
SELECT * FROM test;
UPDATE test SET name = NULL WHERE NO = 2; -- err name은 not null이라서 안된다.자료 삭제 형식 : delete from 테이블명 where 조건
DELETE FROM test WHERE NO = 1 ; -- 부분적인 행 또는 전체 행 삭제
TRUNCATE TABLE test; -- 전체 data 삭제
SELECT * FROM test;
DESC test;
DROP TABLE test; -- table 삭제
SHOW TABLES;기본키 제약조건 : Primary Key - 중복레코드 방지, null 허용X, 칼럼 1개만 부여 가능
-- 방법1
CREATE TABLE aa(bun INT(5) PRIMARY KEY , irum CHAR(10)); -- bun = pk, 중복X, null X
DESC aa;
INSERT INTO aa VALUES(1, 'tom');
INSERT INTO aa VALUES(1, 'james'); -- error
INSERT INTO aa(bun) VALUES(2);
INSERT INTO aa(irum) VALUES('john'); -- error : 번호(pk)도 포함되어야함
SELECT * FROM aa;
SELECT * FROM information_schema.table_constraints WHERE TABLE_NAME='aa'; -- aa table의 제약조건 확인
DROP TABLE aa;
-- 방법2
CREATE TABLE aa(bun INT(5), irum CHAR(10), CONSTRAINT aa_bun_pk PRIMARY KEY(bun)); -- aa_bun_pk라고 primary key에다가 이름을 인위적으로 부여가능
DESC aa;Check 제약조건 : 입력되는 자료의 특정 칼럼값 제한조건
CREATE TABLE aa(bun INT, irum CHAR(10), nai INT(2) CHECK(nai >= 20)); -- 나이의 조건 추가
INSERT INTO aa VALUES(1, 'tom', 23);
SELECT * FROM aa;
INSERT INTO aa VALUES(1, 'tom2',13); -- error : 나이가 20이 안넘음
ALTER TABLE aa ADD CONSTRAINT ck_name CHECK(irum IN('tom','john')); -- 이미 만들어진 테이블에 대해 조건 추가
DROP TABLE aa;unique 제약조건 : 특정칼럼의 동일한 값 입력 불허
CREATE TABLE aa(bun INT, irum CHAR(10) UNIQUE);
DESC aa;
INSERT INTO aa VALUES(1, 'tom');
INSERT INTO aa VALUES(2, 'tom'); -- error : 중복 오류
INSERT INTO aa VALUES(2, 'james');
SELECT * FROM aa;
DROP TABLE aa;default 제약조건 : 특정 칼럼에 초기값 부여
CREATE TABLE aa(bun INT, irum CHAR(10), juso CHAR(50));
ALTER TABLE aa ALTER COLUMN juso SET DEFAULT 'seoul';
INSERT INTO aa VALUES(1, 'tom', '서초1동');
INSERT INTO aa(bun,irum) VALUES(2,'john');
SELECT * FROM aa;외부키 (참조키, foreign key) 제약조건 : 다른 테이블의 칼럼값을 참조. fk 대상은 pk로 한다(중복없는 칼럼)
-- sawon 테이블 생성
CREATE TABLE sawon(bun INT PRIMARY KEY, irum VARCHAR(10), buser CHAR(10))CHARSET=UTF8;
INSERT INTO sawon VALUES(1,'한송이','인사과');
INSERT INTO sawon VALUES(2,'박치기','인사과');
-- sawon 테이블의 bun 을참조하여 테이블 생성
CREATE TABLE gajok(CODE INT PRIMARY KEY, NAME VARCHAR(10), birth DATETIME, sawon_bun INT,
FOREIGN KEY(sawon_bun) REFERENCES sawon(bun))CHARSET=UTF8;
INSERT INTO gajok VALUES(100, '지구인','2000-01-01',1);
INSERT INTO gajok VALUES(200, '가나다',NOW(),1); -- NOW()는 현재 컴퓨터 시간
INSERT INTO gajok VALUES(300, '마당쇠',NOW(),5); -- ERROR : 5번 직원이 없음
DESC gajok; -- MUL이라고 나와있는게 참조되고 있다는 뜻
-- ERROR
DELETE FROM sawon WHERE bun=1; -- 가족 테이블에서 1번 직원 참조중이라서 못지움
DROP TABLE sawon; -- 가족테이블에서 참조중이라서 못지움
-- on delete cascade 부모 테이블의 행이 삭제되는 경우 자식 테이블의 종속행을 함께 삭제칼럼값 자동증가 : auto_increment (Oracle 에서는 없음. 대신에 sequence객체 사용)
CREATE TABLE aa(bun INT auto_increment PRIMARY KEY, irum CHAR(10), juso CHAR(20) DEFAULT '여의도동')CHARSET=UTF8;
INSERT INTO aa(bun,irum) VALUES(1,'한국인');
INSERT INTO aa(irum) VALUES('이기자'); -- int 자동증가
INSERT INTO aa(irum, juso) VALUES('이겨라','역삼동');
INSERT INTO aa VALUES(6,'경민','역삼1동');
INSERT INTO aa VALUES(null,'고길동','역삼2동'); -- bun = 7 이됨
INSERT INTO aa VALUES(0, '신길동','역삼3동'); -- bun = 8 이됨
ALTER TABLE aa AUTO_INCREMENT = 100; -- bun이 100부터 시작함
INSERT INTO aa VALUES(0,'사오정','역삼3동');index(색인) : 검색속도를 증진시키기 위해 칼럼에 색인 부여
사용해야 하는 경우 : 레코드 수가 많을 때, NULL을 많이 포함하고 있는 칼럼, WHERE 조건이 빈번한 경우
자제해야 하는 경우 : 입력, 수정, 삭제가 자주 있는 테이블
CREATE INDEX ind_irum ON aa(irum); -- aa 테이블의 irum 칼럼에 index 추가
ALTER TABLE aa ADD INDEX ind_juso (juso); -- aa 테이블의 juso 칼럼에 index 추가
SHOW INDEX FROM aa; -- index 확인
EXPLAIN SELECT * FROM aa; -- 실행계획 확인
EXPLAIN SELECT * FROM aa WHERE irum='이기자';now(), sysdate() : now는 입력받을때의 시간, sysdate는 출력할때의 시간(여러개 출력시 딜레이 있음)
SELECT NOW();
SELECT SYSDATE();
SELECT NOW(), SLEEP(2), NOW();
SELECT SYSDATE(), SLEEP(2), SYSDATE();
CREATE TABLE abc(irum INT PRIMARY KEY, author CHAR(10), bwrite DATETIME)CHARSET=UTF8;
INSERT INTO abc VALUES(1,'aaa',NOW());
INSERT INTO abc VALUES(2,'bbb',sysdate());테이블 관련, 칼럼 관련 명령
-- 테이블 이름 바꾸기
ALTER TABLE abc RENAME kbs;
-- 칼럼 추가
ALTER TABLE abc ADD(job_id INT(6));
-- 칼럼 이름 바꾸기
ALTER TABLE abc CHANGE job_id job_num INT;
-- 칼럼의 타입을 int 에서 varchar로 바꾸었다
ALTER TABLE abc MODIFY job_num VARCHAR(5);
-- 칼럼 삭제
ALTER TABLE abc DROP column job_num; 연습에 사용할 테이블 출저 : 에이* 아카데미 박*권 선생님 - 데이터 복사 바로가기
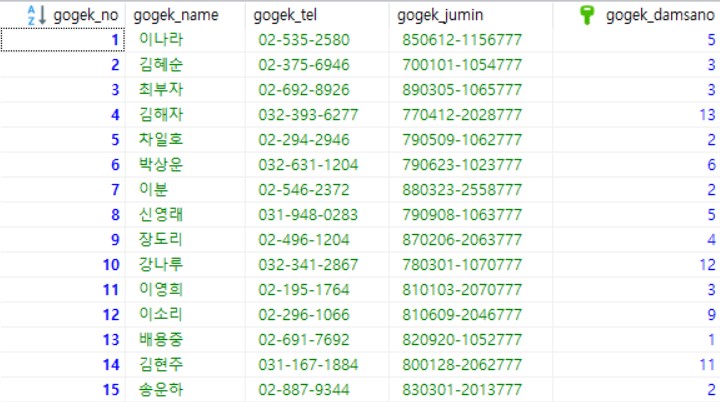
고객 테이블 이미지 바로보기
{kind=link}
부서 테이블 이미지 바로보기
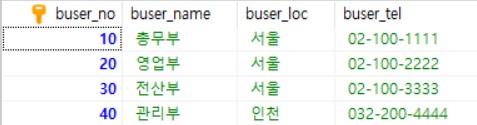{kind=link}
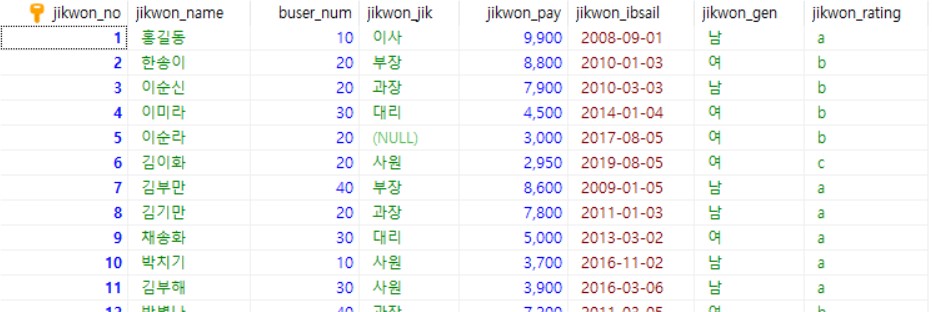
고객 테이블 이미지 바로보기
{kind=link}
상품 테이블 이미지 바로보기
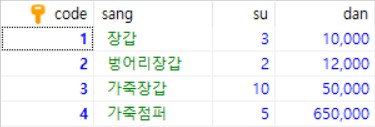{kind=link}
-- 모든 칼럼 모든 레코드 읽기
SELECT * FROM jikwon;
-- 일부 칼럼만 읽기(칼럼의 순서는 무관)
SELECT jikwon_no, jikwon_name, jikwon_pay FROM jikwon;
-- 칼럼에 별명 주기(DB서버에는 이름이 바뀌지 않음)
SELECT jikwon_no AS 사번, jikwon_name AS 이름 from jikwon;
SELECT jikwon_name AS 이름, jikwon_pay AS 연봉, jikwon_pay*0.02 as 세금 FROM jikwon;
-- 가상 테이블(DUAL)
SELECT 10, 12.5, '안녕', 12 + 5, 12 - 5 FROM DUAL;
-- 정렬 : 오름차순 (asc), 내림차순(desc)
SELECT * FROM jikwon ORDER BY jikwon_pay ASC; -- ASC 는 생략가능
SELECT * FROM jikwon ORDER BY jikwon_pay DESC;
SELECT * FROM jikwon ORDER BY buser_num ASC, jikwon_jik DESC, jikwon_pay DESC; -- 여러개도 가능SELECT * FROM jikwon WHERE jikwon_jik = '대리'; -- 레코드 제한
SELECT * FROM jikwon WHERE jikwon_no = 5 OR jikwon_no = 10; -- or 로 특정데이터 보기
SELECT * FROM jikwon WHERE jikwon_no != 5; -- != 과 <> 둘다 부정의 의미임
SELECT * FROM jikwon WHERE jikwon_jik = '사원' AND (jikwon_gen='여' OR jikwon_ibsail >='2017-01-01');
SELECT * FROM jikwon WHERE jikwon_no BETWEEN 5 AND 10; -- between 으로 범위 설정 가능
SELECT * FROM jikwon WHERE jikwon_jik IN('대리','과장','부장'); -- in 연산
SELECT * FROM jikwon WHERE jikwon_pay IS NULL; -- NULL을 조건에 사용하려면 is 를 사용해야한다.
# like 연산 : % (0개 이상의 문자열), _(한지점의 문자)
SELECT * FROM jikwon WHERE jikwon_name LIKE '이%'; -- '이' 로 시작하는 이름
SELECT * FROM jikwon WHERE jikwon_name LIKE '이%라'; -- 이름이 두글자 이상
SELECT * FROM jikwon WHERE jikwon_name LIKE '이_라'; -- 이름이 무조건 세글자
SELECT * FROM gogek WHERE gogek_jumin LIKE '%-1%'; -- 남자만 출력
# limit 로 출력갯수 제한 걸기
SELECT * FROM jikwon LIMIT 5; -- 처음부터 5행 출력
SELECT * FROM jikwon LIMIT 5, 3; -- 6행부터 시작해서 3행 출력
SELECT * FROM jikwon WHERE jikwon_gen='여' LIMIT 5; -- 여자중에 첫 5행 출력
-- json 형식으로 출력 (파이썬 dict 타입으로 입력받기 좋음)
SELECT JSON_OBJECT('jikwon_no',jikwon_no,'jikwon_name',jikwon_name) AS jason_data
FROM jikwon WHERE jikwon_jik='대리';-- 대문자 소문자로 바꾸기
SELECT UPPER('hello'), LOWER('HELLO') FROM DUAL;
-- 문자열 연결
SELECT CONCAT('Hello', 'World') FROM DUAL;
-- 3번째 문자부터 2개 문자 출력 ('ll' 출력)
SELECT SUBSTR('Hello world', 3, 2);
-- 문자열 길이
SELECT length('Hello world');
-- e 가 몇번째 문자열에 있는지
SELECT INSTR('Hello world', 'e');
SELECT POSITION( 'e' IN 'Hello');
-- 1번째부터 찾아서 e 가 어디있는지 찾아라
SELECT LOCATE('e', 'hello world', 1);
-- "***** hello" 출력, RPAD 도 있음
SELECT LPAD('hello', 10, '*');
-- 양쪽 공백 자르기, 한쪽만 자를거면 LTRIM, RTRIM 사용
SELECT TRIM(' aabb bbaa ');
-- . 을 - 로 대체
SELECT REPLACE('010.111.1111', '.', '-'); 숫자 함수
-- 소수점 둘째 짜리까지 표현, 자릿수 안쓰면 정수만 나옴
SELECT ROUND(45.678, 2);
-- 올림, 내림
SELECT CEILING(4.7), FLOOR(4.7);
-- 나머지
SELECT MOD(15, 2), 15 % 2, 15 MOD 2;
-- 가장 큰 수, 가장 작은 수
SELECT GREATEST(15, 4, 21, 7), LEAST(15, 4, 21, 7);날짜 함수
-- 날짜 출력, 날짜를 숫자로 출력 '20,210,510'
SELECT CURDATE(), CURDATE() + 0;
-- 날짜 더하기와 날짜 빼기
SELECT ADDDATE('2021-5-10', 3), ADDDATE('2021-5-10', -300);
SELECT SUBDATE('2021-5-10', 3), SUBDATE('2021-5-10', -300);
-- 특정 시간에 일정한 시간을 추가하기, 시간을 빼려면 DATE_SUB 을 사용한다.
SELECT DATE_ADD(NOW(), INTERVAL 5 MINUTE);
SELECT DATE_ADD('2021-5-10', INTERVAL 5 DAY);
SELECT DATE_ADD('2021-5-10', INTERVAL 5 MONTH);
-- 시간 간의 차이 보기 (YEARDIFF 같은건 없다)
SELECT DATEDIFF(NOW(), '2017-5-8');
SELECT TIMEDIFF('23:23:59', '21:13:49');
-- unit : HOUR, ... DAY, WEEK, QUARTER ...
SELECT TIMESTAMPDIFF(QUARTER,'2020-8-1','2021-5-1'); -- 3 반환, 3분기 차이기 때문
SELECT TIMESTAMPDIFF(DAY,'2020-8-1','2021-5-1'); -- 273 반환
-- 오늘 날짜, 이번달 마지막날, 일년 중 몇번째 날, 주중 몇번째 날
SELECT SYSDATE(), LAST_DAY(SYSDATE()), DAYOFYEAR(SYSDATE()), DAYOFWEEK(SYSDATE());
-- 날짜형 자료 서식을 이용해서 문자열로 반환
SELECT DATE_FORMAT(NOW(), '%Y%m%d'); -- 20210510 반환
SELECT DATE_FORMAT(NOW(), '%Y년 %m월 %d일'); -- 2021년 05월 10일 반환
SELECT DATE_FORMAT(NOW(), '%H:%i:%S'); -- 시간:분:초
SELECT DATE_FORMAT(NOW(), '%j'); -- 일년중 몇번째 날
SELECT DATE_FORMAT(NOW(), '%a'); -- Mon 반환
SELECT DATE_FORMAT(NOW(), '%W'); -- Monday 반환
SELECT jikwon_name, jikwon_ibsail, DATE_FORMAT(jikwon_ibsail, '%W') FROM jikwon LIMIT 5; -- 직원 입사일을 입사한 요일로 볼 수 있다기타 함수
-- 순위 결정 : rank() over(순서) AS rank , (rank 칼럼이 하나 생기고 순위가 적혀있음)
-- rank() 대신 dense_rank() 를 쓸 수 있는데, 둘의 차이는 같은 등수가 있을때 dense_rank는 같은 등수가 있어도 다음등수 한테 다음 숫자 등수를 적용한다.
SELECT jikwon_no, jikwon_name, jikwon_pay, rank() over(ORDER BY jikwon_pay ASC) AS rank FROM jikwon;
-- nv1(value1, value2) : value1 이 null 이면 value2를 사용. value1, value2는 자료형이 일치
SELECT jikwon_no, jikwon_name, nvl(jikwon_jik, '임시직') FROM jikwon LIMIT 10; -- null 이면 임시직으로 표시
-- nv12(value1, value2, value3) : value1 이 null 이면 value3를 사용, null 이 아니면 value2 사용
SELECT jikwon_no, jikwon_name, nvl2(jikwon_jik, '정규직', '임시직') FROM jikwon LIMIT 10; -- null 이 아닌건 정규직, null 이면 임시직
-- nullif(value1, value2) : 두개의 값이 일치하면 null, 일치하지 않으면 value1을 반환
SELECT NULLIF(LENGTH('abcd'), LENGTH('abc')); -- 4 출력
SELECT NULLIF(LENGTH('abcd'), LENGTH('abcd')); -- null 출력SELECT case 10 / 5 when 5 then '안녕' when 2 then '수고'ELSE '잘가' END AS result FROM DUAL; -- 수고 출력
SELECT jikwon_name, case jikwon_pay when 3000 then '어라 연봉 3000' when 3500 then '흠 3500'
ELSE '그외 연봉' END AS result FROM jikwon;
SELECT jikwon_name, jikwon_pay, jikwon_jik, case jikwon_jik when '부장' then jikwon_pay*0.05
when '과장' then jikwon_pay*0.04 ELSE jikwon_pay*0.03 END donation FROM jikwon; -- donation 이라는 새로운 칼럼을 만들어서 거기에다 표시한다형식2 : case when ... then...
SELECT jikwon_name, case when jikwon_gen='남' then 'M' when jikwon_gen='여' then 'F' END AS gender FROM jikwon;
SELECT jikwon_name, jikwon_pay, case
when (2000 - jikwon_pay) > 0 then '2000미만'
when (3000 - jikwon_pay) > 0 then '2000대'
when (4000 - jikwon_pay) > 0 then '3000대'
when (5000 - jikwon_pay) > 0 then '4000대'
when (6000 - jikwon_pay) > 0 then '5000대'
ELSE '6000이상' END pay FROM jikwon;-- 과장들의 합과 평균
SELECT sum(jikwon_pay) AS 합, AVG(jikwon_pay) AS 평균 FROM jikwon WHERE jikwon_jik = '과장';
-- 최대값, 최소값
SELECT MAX(jikwon_pay) AS 최대합, MIN(jikwon_pay) AS 최소 FROM jikwon;
-- 표준편차, 분산
SELECT STDDEV(jikwon_pay) AS 표준편차, VAR_SAMP(jikwon_pay) AS 분산 FROM jikwon;
-- 데이터 갯수
SELECT COUNT(*), COUNT(jikwon_name), COUNT(jikwon_pay) from jikwon; 그룹 함수 (소계 출력) : group by ~ , 그룹 칼럼에는 order by 할 수 없다. 단 최종 반환값에 대한 order by는 가능
-- 남여 각각의 급여의 평균 구하기
SELECT jikwon_gen, AVG(jikwon_pay) FROM jikwon GROUP BY jikwon_gen;
-- 부서별 급여합
SELECT buser_num, SUM(jikwon_pay) FROM jikwon GROUP BY buser_num;
-- 부서별 급여합이 35000원 이상
SELECT buser_num, SUM(jikwon_pay) AS hap FROM jikwon GROUP BY buser_num HAVING hap >= 35000; -- cross join
SELECT jikwon_name, buser_name FROM jikwon, buser; -- 한개의 직원 이름당 모든 부서이름 매칭해서 출력
-- EQUI join : 조건이 =
SELECT jikwon_name, buser_name FROM jikwon, buser WHERE buser_num=buser_no;
SELECT jikwon_name, buser_name FROM jikwon INNER JOIN buser WHERE buser_num=buser_no; -- 결과는 같지만 inner join을 쓴다는것을 명시함
-- NON-EQUI join : 조건이 = 연산자 제외
CREATE TABLE paygrade(grade INT PRIMARY KEY, lpay INT, hpay INT); -- pay 의 등급 테이블
INSERT INTO paygrade VALUES(1, 0, 1999);
INSERT INTO paygrade VALUES(2, 2000, 2999);
INSERT INTO paygrade VALUES(3, 3000, 3999);
INSERT INTO paygrade VALUES(4, 4000, 4999);
INSERT INTO paygrade VALUES(5, 5000, 9999);
SELECT jikwon_no, jikwon_name, jikwon_pay, grade FROM jikwon j, paygrade p
on j.jikwon_pay >= p.lpay AND j.jikwon_pay <= p.hpay;Inner Join : 두개의 테이블 자료에서 일치하는 경우만 출력. 대응되지 않는 자료는 제외
-- 1번 방법 (Oracle 문법)
SELECT a.jikwon_no, a.jikwon_name, b.buser_name FROM jikwon a, buser b
WHERE a.buser_num = b.buser_no AND jikwon_no <= 3;
-- 2번 방법 (ANSI 문법)
SELECT a.jikwon_no, a.jikwon_name, b.buser_name FROM jikwon a INNER JOIN buser b
on a.buser_num = b.buser_no WHERE jikwon_no <= 3; -- on 뒤에는 inner join 조건, where 뒤에는 출력 조건, inner은 지워도 됨Outer Join : 두개의 테이블 자료에서 왼쪽 테이블 자료는 출력. 대응되지 않는 자료는 null로 반환
SELECT jikwon_no, jikwon_name, buser_name FROM jikwon LEFT OUTER JOIN buser ON buser_num = buser_no; -- jikwon_name 전체출력테이블 세개 Join
-- 1번 방법 (Oracle 문법)
SELECT jikwon_name, buser_name, gogek_name FROM jikwon, buser, gogek
WHERE jikwon.buser_num = buser.buser_no AND jikwon.jikwon_no = gogek.gogek_damsano;
-- 2번 방법 (ANSI 문법)
SELECT jikwon_name, buser_name, gogek_name FROM jikwon
left JOIN buser ON jikwon.buser_num = buser.buser_no
left JOIN gogek ON jikwon.jikwon_no = gogek.gogek_damsano;Union : 구조가 일치하는 두 개 이상의 테이블 자료 합치기 (MariaDB는 full join을 지원 안함)
-- 테이블 생성
CREATE TABLE pum1(bun INT, pummok VARCHAR(20))CHARSET=UTF8;
INSERT INTO pum1 VALUES(1,'귤');
INSERT INTO pum1 VALUES(2,'바나나');
INSERT INTO pum1 VALUES(3,'한라봉');
SELECT * FROM pum1;
CREATE TABLE pum2(num INT, sangpum VARCHAR(20))CHARSET=UTF8;
INSERT INTO pum2 VALUES(10,'수박');
INSERT INTO pum2 VALUES(20,'토바토');
INSERT INTO pum2 VALUES(30,'딸기');
INSERT INTO pum2 VALUES(40,'참외');
SELECT bun AS 번호, pummok AS 품명 FROM pum1 UNION SELECT num,sangpum FROM pum2;Merge : 기존에 존재하는 행이 있다면 갱신되고, 없다면 추가된 작업 (Oracle의 merge와는 다르다)
CREATE TABLE mer_tab AS SELECT jikwon_no, jikwon_name, jikwon_pay FROM jikwon WHERE jikwon_no <= 5;
SELECT * FROM mer_tab;
# 박치기 직원과 직급이 같은 직원 출력
-- 1차원적인 방법
SELECT jikwon_jik FROM jikwon WHERE jikwon_name = '박치기';
SELECT * FROM jikwon WHERE jikwon_jik = '사원';
-- subquery 사용
SELECT * FROM jikwon WHERE jikwon_jik = (SELECT jikwon_jik FROM jikwon WHERE jikwon_name = '박치기');사용예시
-- 직급이 대리 중 가장 먼저 입사한 직원은?
SELECT * FROM jikwon WHERE jikwon_jik = '대리' AND
jikwon_ibsail = (SELECT MIN(jikwon_ibsail) FROM jikwon WHERE jikwon_jik='대리'); -- 2013-02-05
-- 인천에 근무 하는 직원 출력
SELECT * FROM jikwon WHERE buser_num = (SELECT buser_no FROM buser WHERE buser_loc='인천');
-- 인천 이외 지역에 근무하는 직원 출력
SELECT * FROM jikwon WHERE buser_num IN (SELECT buser_no FROM buser WHERE NOT buser_loc = '인천');
-- 최부자 고객과 담당직원이 같은 고객자료 출력
SELECT * FROM gogek WHERE gogek_damsano = (SELECT gogek_damsano FROM gogek WHERE gogek_name = '최부자');
-- 차일호 고객과 나이가 같은 모든 고객 출력
SELECT * FROM gogek WHERE SUBSTR(gogek_jumin,1,2)=(SELECT SUBSTR(gogek_jumin,1,2)
FROM gogek WHERE gogek_name = '차일호');
any, all 연산자 사용
< ANY : subquery 의 반환값중 최대값 보다 작은 ~
> ANY : subquery 의 반환값중 최소값 보다 큰 ~
< ALL : subquery 의 반환값중 최소값 보다 작은 ~
> ALL : subquery 의 반환값중 최대값 보다 큰 ~
-- 대리의 최대값 보다 작은 연봉을 받는 직원 출력
SELECT jikwon_no, jikwon_name, jikwon_pay FROM jikwon
WHERE jikwon_pay < ANY(SELECT jikwon_pay FROM jikwon WHERE jikwon_jik='대리');
-- 30번 부서의 최고 급여자 보다 급여를 많이 받는 직원?
SELECT jikwon_no, jikwon_name, jikwon_pay FROM jikwon
WHERE jikwon_pay > ALL(SELECT jikwon_pay FROM jikwon WHERE buser_num=30);from 절에 사용하는 subquery
-- 전체 평균연봉과 최대 연봉 사이의 연봉을 받는 직원 출력
SELECT jikwon_no, jikwon_name, jikwon_pay FROM jikwon a, (SELECT AVG(jikwon_pay) avgs, MAX(jikwon_pay) maxs
FROM jikwon) b WHERE a.jikwon_pay BETWEEN b.avgs AND b.maxs;
-- 각 부서별로 최고 연봉을 받는 직원 출력
SELECT a.jikwon_no, a.jikwon_name, a.jikwon_pay FROM jikwon a, (SELECT buser_num, MAX(jikwon_pay) maxpay
FROM jikwon GROUP BY buser_num) b WHERE a.buser_num = b.buser_num AND a.jikwon_pay = b.maxpay;group by의 having 절에 subquery
-- 부서별 평균연봉 중 20번 부서의 평균연봉보다 큰 자료 출력
SELECT buser_num, AVG(jikwon_pay) FROM jikwon GROUP BY buser_num
HAVING AVG(jikwon_pay) > (SELECT AVG(jikwon_pay) FROM jikwon WHERE buser_num=20);exists 연산자
-- 직원이 있는 부서 출력
SELECT buser_name, buser_loc FROM buser bu
WHERE EXISTS(SELECT 'imsi' FROM jikwon WHERE buser_num=buser_no);
-- 직원이 없는 부서 출력
SELECT buser_name, buser_loc FROM buser bu
WHERE not EXISTS(SELECT 'imsi' FROM jikwon WHERE buser_num=buser_no);상관 서브쿼리 : 안쪽 질의에서 바깥쪽 질의를 참조하고, 다시 안쪽의 결과를 바깥쪽 질의에 참조하는 형태
-- 각 부서의 최대 급여자는? 각 부서별로 최고 연봉을 받은 직원 출력
SELECT * FROM jikwon a WHERE a.jikwon_pay = (SELECT MAX(b.jikwon_pay) FROM jikwon b
WHERE a.buser_num=b.buser_num);
-- 급여순위 3위 이내의 자료 출력(내림차순)
SELECT jikwon_name, jikwon_pay FROM jikwon a
WHERE 3 > (SELECT COUNT(*) FROM jikwon b WHERE b.jikwon_pay < a.jikwon_pay) AND jikwon_pay IS NOT NULL
ORDER BY jikwon_pay DESC;
subquery를 이용한 create, insert, update, delete
-- subquery를 이용한 create, insert, update, delete
-- create
CREATE TABLE jik1 AS SELECT * FROM jikwon;
CREATE TABLE jik2 AS SELECT * FROM jikwon where 1=0; -- 구조만 있는 테이블(칼럼만 생성됨)
--insert
INSERT INTO jik2 SELECT * FROM jikwon WHERE jikwon_jik='과장'; -- 과장 직원 데이터를 입력
INSERT INTO jik2(jikwon_no,jikwon_name,buser_num,jikwon_jik) SELECT jikwon_no,jikwon_name,buser_num,jikwon_jik
FROM jikwon WHERE jikwon_jik='대리'; -- 대리 직원 데이터 입력
-- update
UPDATE jik1 SET jikwon_jik=(SELECT jikwon_jik FROM jikwon WHERE jikwon_name='이순신') WHERE jikwon_no=2;
-- delete
DELETE FROM jik1 WHERE jikwon_no IN (SELECT DISTINCT gogek_damsano FROM gogek); -- 고객을 관리하는 직원을 지우기단위별 데이터 처리를 말함. 논리적인 작업 단위
insert, update, delete 등의 작업이 있는 경우 변화된 자료에 마무리. commit, rollback을 사용.
데이터 일관성 보장
CREATE TABLE jiktab AS SELECT * FROM jikwon;
SHOW VARIABLES LIKE 'autocommit%'; -- autocommit 이 켜져 있는지 확인, TRUE 일때 commit, rollback을 자동으로 갱신한다.
SET autocommit = FALSE; -- autocommit 을 취소 하는 명령어, 수동으로 전환
SET autocommit = TRUE; commit, rollback 연습1
SET autocommit = FALSE;
DELETE FROM jiktab WHERE jikwon_no =2; -- transaction 시작, command 창에서 확인하면 아직 지워지지 않았음
COMMIT; -- transaction 종료, command 창에서도 지워져 있음
DELETE FROM jiktab WHERE jikwon_no =3; -- transaction 시작
ROLLBACK; -- transaction 종료, 지워지지 않았음.
SET autocommit = TRUE; commit, rollback 연습2
SET autocommit = FALSE;
UPDATE jiktab SET jikwon_pay = 10000 WHERE jikwon_no=3;
SAVEPOINT a; -- 여기서 한번 저장했음
UPDATE jiktab SET jikwon_pay = 11000 WHERE jikwon_no=4;
ROLLBACK TO SAVEPOINT a; -- a 지점으로 롤백
UPDATE jiktab SET jikwon_pay = 12000 WHERE jikwon_no=5;
COMMIT;
-- deadlocks : transaction이 종료되지 않으면 DB 서버의 다른 사용자의 진행을 막고 충돌하게 된다.
-- 반드시 commit 이나 rollback 에 의해 transaction이 종료 되도록 해야한다.물리적인 테이블을 근거로 select문의 조건을 파일로 작성한 후 view를 실행시켜 테이블 처럼 사용
물리적인 테이블을 매번 작성하지 않으므로 메모리 절량. 보안을 강화할 수 있다.
형식 : create [or replace] view 뷰파일명 as select 문
-- 새로운 테이블을 만들면 메모리 소모가 큼.
CREATE TABLE abc as
SELECT jikwon_no, jikwon_name, buser_name, buser_tel FROM jikwon
INNER JOIN buser ON buser_num=buser_no WHERE jikwon_jik='대리';
-- view를 사용하면 조건만 파일로 저장되고 테이블 생성 안됨
CREATE VIEW abc as
SELECT jikwon_no, jikwon_name, buser_name, buser_tel FROM jikwon
INNER JOIN buser ON buser_num=buser_no WHERE jikwon_jik='대리'; .
-- replace까지 사용하면 view 파일에 덮어씌우기 가능
CREATE or REPLACE VIEW v_a AS
SELECT jikwon_no, jikwon_name, jikwon_pay FROM jikwon WHERE jikwon_ibsail < '2015-12-31';
-- 뷰파일 지우기
DROP VIEW v_a;
-- 뷰파일 보는법
SELECT * FROM v_a;
-- view file 목록보기
SHOW FULL TABLES IN test WHERE table_type like 'view'; 사용예시
-- 김씨와 박씨 직원을 view 파일로 만들기
CREATE VIEW v_b AS SELECT * FROM jikwon WHERE jikwon_name LIKE '김%' OR jikwon_name LIKE '박%';
SELECT jikwon_name AS 이름, jikwon_pay AS 연봉 FROM v_b; -- 뷰파일은 테이블과 같이 이런 처리도 가능하다.
-- update, delete, insert
UPDATE 뷰파일 SET jikwon_name='김치국' WHERE jikwon_name='김부만'; -- view 파일을 갱신하면 원본 자료가 변경된다, 왠만하면 한테이블 씩 변경
DELETE FROM 뷰파일 WHERE jikwon_name = '박하나'; -- 원본에서도 삭제된다, 그러나 join에 의한 뷰는 삭제 불가
INSERT INTO 뷰파일 WHERE VALUES(31,'파이썬',10,9998); -- 원본에서도 추가된다DB 서버를 사용하는 클라이언트에게 별도의 계정을 주고 자신의 계정으로만 DB자료를 공유하도록 할 수 있다.
각 계정별 권한을 자격에 맞게 부여해 권한을 행사
-- 계정 생성 ('사용자 계정'@'호스트' IDENTIFIED BY '비밀번호')
CREATE USER 'tester1'@'localhost' IDENTIFIED BY '1111'; -- 로컬 접속 계정
CREATE USER 'tester2'@'%' IDENTIFIED BY '2222'; -- 원격 접속 계정
-- 계정의 권한 보기
SHOW GRANTS FOR tester1@localhost;
-- 권한 부여
GRANT ALL PRIVILEGES ON *.* TO tester@localhost IDENTIFIED BY '1111'; -- 모든 권한 다주기
GRANT ALL PRIVILEGES ON ourdb.* TO 'testuser1'@'localhost';
FLUSH PRIVILEGES; -- 권한 설정을 새롭게 반영 (새로고침)
-- 모든 사용자 목록 보기
SELECT USER FROM mysql.user;
-- 계정 삭제
DROP USER 'tester1'@'localhost';사용예시
CREATE DATABASE ourdb; -- 데이터 베이스 생성
USE ourdb;
CREATE TABLE abctab(NO INT PRIMARY KEY, NAME VARCHAR(10));
INSERT INTO abctab VALUES(1,'aa');
INSERT INTO abctab VALUES(2,'bb');
GRANT ALL PRIVILEGES ON ourdb.* TO 'testuser1'@'localhost'; -- ourdb 데이터베이스 사용의 모든 권한을 줌
GRANT SELECT, INSERT ON ourdb.* TO 'testuser2'@'localhost'; -- ourdb 데이터베이스 안의 select, insert 권한을 줌
FLUSH PRIVILEGES;
REVOKE ALL ON ourdb.* FROM 'testuser1'@'localhost'; -- ourdb 데이터베이스 사용의 모든 권한을 뺏음
FLUSH PRIVILEGES;SQL문의 집합으로 어떠한 동작을 일괄처리하기 위해 사용. 프로그래밍 가능
절차적인 프로그래밍이 가능하며 PL / SQL 이라고도 한다
DECLARE(선언부) ~ BEGIN(실행부) ~ EXCEPTION(예외처리부) ~ END 로 이루어 진다
SHOW PROCEDURE STATUS; -- procedure 목록 확인
DELIMITER // -- 구분문자를 // 로 바꾼다
CREATE OR REPLACE PROCEDURE sp_1(a INT, b INT)
BEGIN
DECLARE X, Y INT DEFAULT 0; -- 변수 선언. 대소문자 구분 안함
SET X = 10;
SELECT X, Y;
SELECT a + b;
END;
// -- 여기까지 프로시저 라는 뜻임
DELIMITER ; -- 구분문자를 ; 로 바꾼다
CALL sp_1(1,3);
-- 테이블과 연동
DELIMITER //
CREATE OR REPLACE PROCEDURE sp_2(ar1 INT, ar2 INT)
BEGIN
SELECT * FROM jikwon WHERE jikwon_no = ar1;
SELECT * FROM jikwon WHERE jikwon_no = ar2;
END
//
DELIMITER ;
CALL sp_2(6, 9);
if 문 사용
DELIMITER //
CREATE OR REPLACE PROCEDURE sp_3(IN jik VARCHAR(20) CHARSET utf8, num INT) -- IN은 입력용이라는 의미, OUT은 출력용
BEGIN
SELECT jik;
SELECT * FROM jikwon WHERE jikwon_jik = jik;
if(num = 10) then
SELECT * FROM jikwon WHERE buser_num = 10;
ELSEIF (num = 20) then
SELECT * FROM jikwon WHERE buser_num = 20;
ELSE
SELECT * FROM jikwon WHERE buser_num != 10;
END if;
END
//
DELIMITER ;
CALL sp_3('대리', 20);while 문 사용
DELIMITER //
CREATE OR REPLACE PROCEDURE sp_4()
BEGIN
DECLARE X INT;
DECLARE str VARCHAR(255);
SET X = 1;
SET str = '';
while X <= 5 DO
SET str = CONCAT(str, X, ',');
SET X = X + 1;
END while;
SELECT str;
END
//
DELIMITER ;
CALL sp_4;repeat 문 사용
DELIMITER //
CREATE OR REPLACE PROCEDURE sp_5()
BEGIN
DECLARE X INT;
DECLARE str VARCHAR(255);
SET X = 1;
SET str = '';
repeat
SET str = CONCAT(str, X, ',');
SET X = X + 1;
until X > 5
END repeat;
SELECT str;
END
//
DELIMITER ;
CALL sp_5;사용자 정의 함수
-- bmi 계산
DELIMITER //
CREATE OR REPLACE FUNCTION fu1(height INT) RETURNS DOUBLE -- double은 실수 type을 의미함
BEGIN
RETURN height * height * 22 / 10000; -- bmi = 22 일때 적정 몸무게 출력
END;
//
DELIMITER ;
SELECT fu1(187);
-- 직원 전체의 연봉 평균 계산 함수
DELIMITER //
CREATE OR REPLACE FUNCTION fu2() RETURNS DOUBLE -- double은 실수 type을 의미함
BEGIN
DECLARE r DOUBLE; -- 변수 설정
SELECT AVG(jikwon_pay) INTO r FROM jikwon;
RETURN r;
END;
//
DELIMITER ;
SELECT fu2();
-- 각 직원 연봉의 10% 반환
DELIMITER //
CREATE OR REPLACE FUNCTION fu3(NO int) RETURNS INT
BEGIN
DECLARE pay INT;
SET pay = 0;
SELECT jikwon_pay * 0.1 INTO pay FROM jikwon WHERE jikwon_no = no;
RETURN pay;
END
//
DELIMITER ;
SELECT fu3(3);
-- 부서번호를 입력하면 부서명 반환
DELIMITER //
CREATE OR REPLACE FUNCTION fu4(BNO int) RETURNS VARCHAR(10) CHARSET UTF8
BEGIN
DECLARE bname VARCHAR(10) CHARSET UTF8;
SELECT buser_name INTO bname FROM buser WHERE buser_no=BNO;
RETURN bname;
END
//
DELIMITER ;
SELECT fu4(10);
SELECT jikwon_no, jikwon_name, fu4(buser_num), jikwon_pay FROM jikwon WHERE jikwon_jik='대리';
Categories :
Practice